What is Data Lakehouse?
This
article on the data lakehouse will aim to introduce the data lakehouse and describe
what is new and different about it.
The Data Lakehouse Explained
The term
“lakehouse” is derived from the two foundational technologies the data lake and
the data warehouse. Lakehouse is a concept or data paradigm that can be built
using different set of technologies to fulfill the objectives.

At a high
level, the data lakehouse consists of the following components:
·
Data lakehouse
·
Data lake
·
Object storage
The data
lakehouse describes a data warehouse-like service that runs against a data
lake, which sits on top of an object storage. These services are distributed in
the sense that they are not consolidated into a single, monolithic application,
as with a relational database. They are independent in the sense
that they are loosely coupled or decoupled -- that is, they expose
well-documented interfaces that permit them to communicate and exchange data
with one another. Loose coupling is a foundational concept in distributed
software architecture and a defining characteristic of cloud services and
cloud-native design.
How Does the Data Lakehouse Work?
From the
top to the bottom of the data lakehouse stack, each constituent service is more
specialized than the service that sits “underneath” it.
·
Data lakehouse: The data lakehouse is a highly
specialized abstraction layer or a semantic layer. That exposes data in the
lake for operational reporting, ad hoc query, historical analysis, planning and
forecasting, and other data warehousing workloads.
·
Data lake: The data lake is a less specialized
abstraction layer. That schematizes and manages the objects contained in an
underlying object storage service, and schedules operations to be performed on
them. The data lake can efficiently ingest and store data of every type. Like structured
relational data (which it persists in a columnar object format), semi
structured (text, logs, documents), and un or multi structured (files of
any type) data.
·
Object storage: As the foundation of the
lakehouse stack, object storage consists of an even more basic
abstraction layer: A performant and cost-effective means of provisioning and
scaling storage, on-demand storage.
Again,
for data lakehouse to work, the architecture must be loosely coupled. For
example, several public cloud SQL query services, when combined with cloud data
lake and object storage services, can be used to create the data lakehouse. This
solution is the “ideal” data lakehouse in the sense that it is a rigorous
implementation of a formal, loosely coupled architectural design. The SQL query
service runs against the data lake service, which sits on top of an object
storage service. Subscribers instantiate prebuilt queries, views, and data modeling
logic in the SQL query service, which functions like a semantic layer. And this
whole solution is the data lakehouse.
This
implementation is distinct from the data lakehouse services that Databricks, Dremio,
and others market. These implementations are coupled to a specific data lake
implementation, with the result that deploying the lakehouse means, in effect,
deploying each vendor’s data lake service, too.
The
formal rigor of an ideal data lakehouse implementation has one obvious benefit:
It is notionally easier to replace one type of service (for example, a SQL
query) with an equivalent commercial or open-source service.
What Is New and Different About the Data
Lakehouse?
It all
starts with the data lake. Again, the data lakehouse is a higher-level
abstraction superimposed over the data in the lake. The lake usually consists
of several zones, the names, and purposes of which vary according to
implementation. At a minimum, Lakehouse consist of the following:
·
one or more ingest or landing zones for data.
·
one or more staging zones, in which experts work with and
engineer data; and
·
one or more "curated" zones, in which prepared and engineered
data is made available for access.
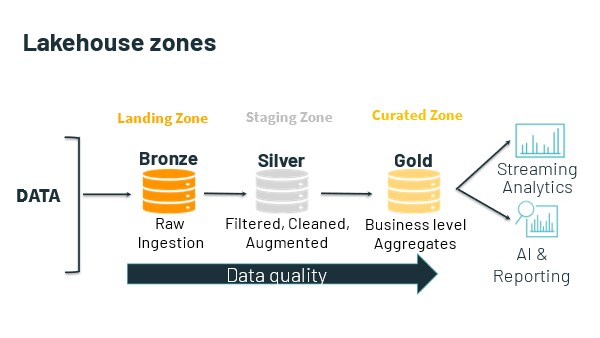
Usually, the data lake is home to all an organization’s useful data. This data is already there. So, the data lakehouse begins with query against this data where it lives.
It is in
the curated (GOLD) zone of the data lake that the data lakehouse itself lives. Although
it is also able to access and query against data that is stored in the lake’s
other zones. In this way the data lakehouse can support not only traditional
data warehousing use cases, but also innovative use cases such as data science
and machine learning and artificial intelligence engineering.
The
following are the advantages of the data lakehouse.
1. More
agile and less fragile than the data warehouse
Querying
against data in the lake eliminates the multistep process involved in moving
the data,
engineering it and moving it again before loading it into the warehouse. (In
extract, load, transform [ELT], data is engineered in the warehouse itself.
This removes a second data movement operation.) This process is closely
associated with the use of extract, transform, load (ETL) software. With the
data lakehouse, instead of modeling data twice -- first, during the ETL phase,
and, second, to design denormalized views for a semantic layer, or to
instantiate data modeling and data engineering logic in code -- experts need
only perform this second modeling step.
The result
is less complicated (and less costly) ETL, and a less fragile data lakehouse.
2. Query
against data in place in the data lake
Querying
against the data lakehouse makes sense because all an organization’s
business-critical data is already there -- that is, in the data lake. Data
gets stored into the lake from sensors and other sources, from workload, business
apps and services, from online transaction processing systems, from
subscription feeds, and so on.
The
strong claim is that the extra ability to query against data in the whole of
the lake -- that is, its staging and non-curated zones -- can accelerate data
delivery for time-sensitive use cases. A related claim is that it is useful to
query against data in the lakehouse, even if an organization already has a data
warehouse, at least for some time-sensitive use cases or practices.
The weak
claim is that the lakehouse is a suitable replacement for the data warehouse.
3. Query
against relational, semi-structured, and multi-structured data
The data
lakehouse sits atop the data lake, which ingests, stores and manages data of
every type. Moreover, the lake’s curated zone need not be restricted solely to
relational data: Organizations can store and model time series, graph, document,
and other types of data there. Even though this is possible with a data
warehouse, it is not cost-effective.
4. More
rapidly provision data for time-sensitive use cases
Expert
users -- say, scientists working on a clinical trial -- can access raw trial
results in the data lake’s non-curated ingest zone, or in a special zone
created for this purpose. This data is not provisioned for access by all users;
only expert users who understand the clinical data are permitted to access and
work with it. Again, this and similar scenarios are possible because the lake
functions as a central hub for data collection, access, and governance. The
necessary data is already there, in the data lake’s raw or staging zones,
“outside” the data lakehouse’s strictly governed zone. The organization is just
giving a certain class of privileged experts early access to it.
5. Better
support for DevOps and software engineering
Unlike
the classic data warehouse, the lake and the lakehouse expose various access
APIs, in addition to a SQL query interface.
For
example, instead of relying on ODBC/JDBC interfaces and ORM techniques to
acquire and transform data from the lakehouse -- or using ETL software that
mandates the use of its own tool-specific programming language and IDE design
facility -- a software engineer can use preferred dev tools and cloud services,
so long as these are also supported by team’s DevOps toolchain. The data
lake/lakehouse, with its diversity of data exchange methods, its abundance
of co-local compute services, and, not least, the access it affords to raw
data, is arguably a better “player” in the DevOps universe than is the
data warehouse. In theory, it supports a larger variety of use cases, practices,
and consumers -- especially expert users.
True,
most RDBMSs, especially cloud PaaS RDBMSs, now support access using RESTful
APIs and language-specific SDKs. This does not change the fact that some
experts, particularly software engineers, are not -- at all -- charmed of the
RDBMS.
Another
consideration is that the data warehouse, especially, is a strictly governed
repository. The data lakehouse imposes its own governance strictures, but the
lake’s other zones can be less strictly governed. This makes the combination of
the data lake + data lakehouse suitable for practices and use cases that
require time-sensitive, raw, lightly prepared, so on, data (such as ML
engineering).
6. Support
more and different types of analytic practices.
For
expert users, the data lakehouse simplifies the task of accessing and working
with raw or semi-/multi-structured data.
Data
scientists, ML, and AI engineers, and, not least, data engineers can put data into the
lake, acquire data from it, and take advantage of its co-locality with an
assortment of intra-cloud compute services to engineer data. Experts need not
use SQL; rather, they can work with their
preferred languages, libraries, services and tools (notebooks,
editors, and favorite CLI shells). They can also use their preferred
conceptual vocabularies. So, for example, experts can build and work with data
pipelines, as distinct to designing ETL jobs. In place of an ETL tool, they can
use a tool such as Apache Airflow to schedule, orchestrate, and monitor
workflows.
Summary
It is
impossible to untie the value and usefulness of the data lakehouse from that of
the data lake. In theory, the combination of the two -- that is, the data
lakehouse layered atop the data lake -- outperforms the usefulness, flexibility,
and capabilities of the data warehouse. The discussion above sometimes refers
separately to the data lake and to the data lakehouse. What is usually,
however, is the co-locality of the data lakehouse with the data lake -- the
“data lake/house,” if you like.
No comments:
Post a Comment